来源:全球半导体观察 原作者:张明花
人工智能/机器学习、高性能计算、数据中心等应用市场兴起,催生高带宽内存HBM(High Bandwidth Memory)并推动着其向前走更新迭代。如今,HBM来到第四代,尽管固态存储协会(JEDEC)尚未发布推出HBM3的相关规范,产业链各厂商已早早布局。
10月20日,SK海力士宣布业界首次成功开发现有最佳规格的HBM3 DRAM。这是SK海力士去年7月开始批量生产HBM2E DRAM后,时隔仅1年零3个月开发了HBM3。
据了解,SK海力士研发的HBM3可每秒处理819GB的数据,相当于可在一秒内传输163部全高清(Full-HD)电影(每部5GB),与上一代HBM2E相比,速度提高了约78%;内置ECC校检(On Die-Error Correction Code),可自身修复DRAM单元的数据的错误,产品可靠性大幅提高。

图片来源:SK海力士官网
SK海力士HBM3将以16GB和24GB两种容量上市。据悉,24GB是目前业界最大的容量,为了实现24GB,SK海力士技术团队将单品DRAM芯片的高度磨削到约30微米(μm, 10-6m),相当于A4纸厚度的1/3,然后使用TSV技术(Through Silicon Via,硅通孔技术)垂直连接12个芯片。
随着SK海力士成功开发HBM3,HBM开始挺进3.0时代,IP厂商亦已先行布局HBM3。
10月7日,Synopsys宣布推出业界首个完整的HBM3 IP解决方案,包括用于2.5D多芯片封装系统的控制器、PHY和验证IP。据了解,Synopsys的DesignWare HBM3控制器与PHY IP基于经芯片验证过的HBM2E IP打造,而HBM3 PHY IP基于5nm制程打造,每个引脚的速率可达7200 Mbps,内存带宽最高可提升至921GB/s。
值得一提的是,在Synopsys的新闻稿中,SK海力士、三星电子、美光等内存厂商均表示将致力于开发HBM3内存。
除了Synopsys,今年8月美国内存IP核供应商Rambus宣布推出其支持HBM3的内存接口子系统,内含完全集成的PHY和数字控制器,数据传输速率达8.4 Gbps,可提供超过1TB/s的带宽,是HBM2E内存子系统的两倍以上。Rambus预计,其HBM3内存将于2022年末或2023年初流片,实际应用于数据中心、AI、HPC等领域。
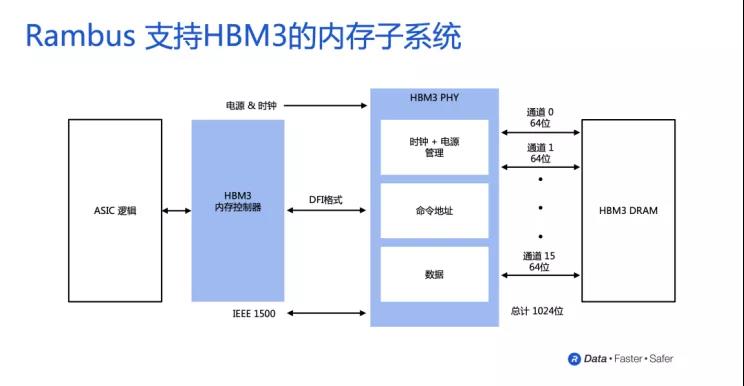
图片来源:Rambus
而更早些时候,中国台湾地区的创意电子于6月发布基于台积电CoWoS技术的AI/HPC/网络平台,搭载7.2Gbps HBM3控制器。
三星电子虽然目前尚未发布HBM3,但从披露的信息来看,其在HBM方面亦正持续发力。
今年2月,三星电子发布其集成AI处理器新一代芯片HBM-PIM(processing-in-memory),可提供最高达1.2 TFLOPS的嵌入式计算能力,从而使内存芯片本身能够执行通常由CPU、GPU、ASIC或FPGA处理的工作。在这款HBM-PIM芯片中,三星电子利用PIM技术,将AI处理器搭载于HBM2 Aquabolt中,可提升两倍性能,同时将功耗降低70%以上。
据介绍,HBM-PIM芯片将AI引擎引入每个存储库,从而将处理操作转移到HBM本身。这种新型内存的设计是为了减轻内存与一般处理器之间转移数据的负担,因为实际应用中,这种负担无论在功耗还是时间上,往往比真正的计算操作消耗更大。三星还表示,使用这种新内存不需要任何软件或硬件变化(包括内存控制器),从而可以被市场更快地采用。

图片来源:三星电子
对于HBM而言,三星电子的HBM-PIM提供了另一种方式,不过按照三星电子在Synopsys的新闻稿中所表达的态度,三星电子也将继续推进开发HBM3。
此外,三星电子5月宣布开发出能将逻辑芯片(Logic Chip)和4颗HBM封装在一起的新一代2.5D封装技术“I-Cube4”,该技术可用于高性能计算(HPC)、AI、5G、云、数据中心等各种领域。据悉,三星目前也正在开发更先进、更复杂的I-Cube6,可同时封装6颗HBM以及更复杂的2.5D/3D混合封装技术。
在内存/IP厂商在HBM领域的升级竞赛持续进行的同时,HBM正在得到更多应用,主要厂商包括如AMD、英伟达、英特尔等。
AMD和英伟达两大显卡厂商曾多次在其产品上采用HBM。据了解,AMD当初携手SK海力士研发HBM,并在其Fury显卡采用全球首款HBM;2017年AMD旗下Vega显卡使用HBM 2;2019年AMD Radeon VII显卡搭载的亦为HBM2。
英伟达方面,其2016年发布的首个采用帕斯卡架构的显卡Tesla P100就搭载了HBM2,包括后面的Tesla V100也采用了HBM2;2017年初,英伟达发布的Quadro系列专业卡中的旗舰GP100亦采用了HBM2;2020年5月,英伟达推出的Tesla A100计算卡也搭载了容量40GB HBM2;今年6月,英伟达升级了A100 PCIe GPU加速器,配备80GB HBM2e显存。
而英特尔更是将在其两款新品中用到HBM。
今年8月,英特尔在其架构日上介绍基于Xe HPC微架构的全新数据中心GPU架构Ponte Vecchio。Ponte Vecchio芯片由几个以单元显示的复杂设计构成,包括计算单元、Rambo单元、Xe链路单元以及包含高速HBM内存的基础单元。基础单元是所有复杂的I/O和高带宽组件与SoC基础设施——PCIe Gen5、HBM2e内存、连接不同单元MDFI链路和EMIB桥接。
英特尔也将HBM用在其下一代服务器CPU Sapphire Rapids上。据英特尔介绍,在内存方面,Sapphire Rapids除了支持DDR5和英特尔@傲腾™内存技术,还提供了一个产品版本,该版本在封装中集成了HBM技术,可在HPC、AI、机器学习和内存数据分析工作负载中普遍存在的密集并行计算中实现高性能。
近期外媒消息称,一名工程师曝光了英特尔Sapphire Rapids的照片,曝光的照片显示,Sapphire Rapids封装了四颗CCD核心,每颗核心旁均配备两片长方形的HBM内存芯片。爆料者表示这可能是HBM2E,每颗处理器核心将具备两条1024位内存总线。
值得一提的是,今年7月外媒消息称,AMD正在研发代号为Genoa的下一代EPYC霄龙服务器处理器,采用Zen 4架构。这一处理器将首次配备HBM内存,目的是与英特尔下一代服务器CPU Sapphire Rapids竞争。
若消息属实,那英特尔和AMD均将在CPU上采用HBM,这也意味着HBM的应用不再局限于显卡,其在服务器领域的应用将有望更加广泛。
HBM主要是通过TSV技术进行芯片堆叠,以增加吞吐量并克服单一封装内带宽的限制,将数个DRAM裸片像摩天大厦中的楼层一样垂直堆叠,裸片之间用TVS技术连接。
凭借TSV方式,HBM大幅提高了容量和数据传输速率,与传统内存技术相比,HBM具有更高带宽、更多I/O数量、更低功耗、更小尺寸,可应用于高性能计算(HPC)、超级计算机、大型数据中心、人工智能/深度学习、云计算等领域。
回顾HBM性能的历史演进,第一代HBM数据传输速率大概可达1Gbps;2016年推出的第二代产品HBM2,最高数据传输速率可达2Gbps;2018年,第三代产品HBM2E的最高数据传输速率已经可达3.6Gbps。如今,SK海力士已研发出第四代产品HBM3,此后HBM3预计仍将持续发力,在数据传输速率上有更大的提升。
从性能来看,HBM无疑是非常出色的,其在数据传输的速率、带宽以及密度上都有着巨大的优势。不过,目前HBM仍主要应用于数据中心等应用领域,主要在于服务器市场,其最大的限制条件在于成本,对成本比较敏感的应用领域如消费级市场而言,HBM的使用门槛仍较高。据了解,HBM所采用2.5封装/3D堆叠技术是其成本偏高的重要原因。
尽管HBM已更迭到第四代,但正如Rambus IP核产品营销高级总监Frank Ferro此前在接受采访时所言,HBM现在依旧处于相对早期的阶段,其未来还有很长的一段路要走。而可预见的是,随着越来越多的厂商在人工智能/机器学习等领域不断发力,内存产品设计的复杂性正在快速上升,并对带宽提出了更高的要求,不断上升的宽带需求将持续驱动HBM发展。
2021年,芯片产能紧缺席卷全球,半导体产业迎来结构性转变,存储行业亦面临着巨大的机遇和挑战。面对发展良机与各种不确定性因素,国内外存储企业该如何把握机遇实现突围?存储技术演进又将迎来哪些新趋势?
微信
精彩资讯扫码关注

新浪
成为我们的小粉丝
领英
成为我们的小粉丝
RSS
实时更新科技资讯

 微信公众平台
微信公众平台